
// wszystkie materiały zostały zebrane w podsumowaniu cyklu.
W poprzednim poście opowiedziałem ogólnie czym są Bounded Contexty. Jednak sama idea jest niczym bez możliwości wdrożenia jej w życie. Poniżej przygotowałem krótki opis jak można konteksty wdrożyć do naszych systemów. Opiera się on na schemacie aplikacji webowej z bazą danych SQL, ale łatwo jest go przenieść również na inne rodzaje architektur.
W czym problem?
Aplikacja bez kontekstów używa tych samych klas / serwisów / struktur bazodanowych do rozwiązywania różnych problemów. Nie ma w tym nic niewłaściwego, kiedy nasz system startuje - nie znamy wtedy jeszcze szczególnych wymagań, przez co wszystko dobrze mieści się w jednym modelu. Jednak długofalowo taki sposób jego tworzenia aplikacji potrafi mocno utrudniać jej rozwój i utrzymanie. Biorąc za przykład system e-commercowy, skutki takiego rozwiązania mogą być następujące:
- tabela Order będzie zawierała ogromną ilość kolumn wymaganych do wszystkich możliwych przypadków użycia
- serwis OrderService będzie miał dziesiątki mieszających się metod
- klasa OrderViewModel będzie zawierał pola reużywane w wielu odmiennych widokach
W takim układzie jakakolwiek zmiana wymagań będzie skutkowała dotkliwą refaktoryzacją dużej części systemu.
Schemat Bounded Contextu w systemie
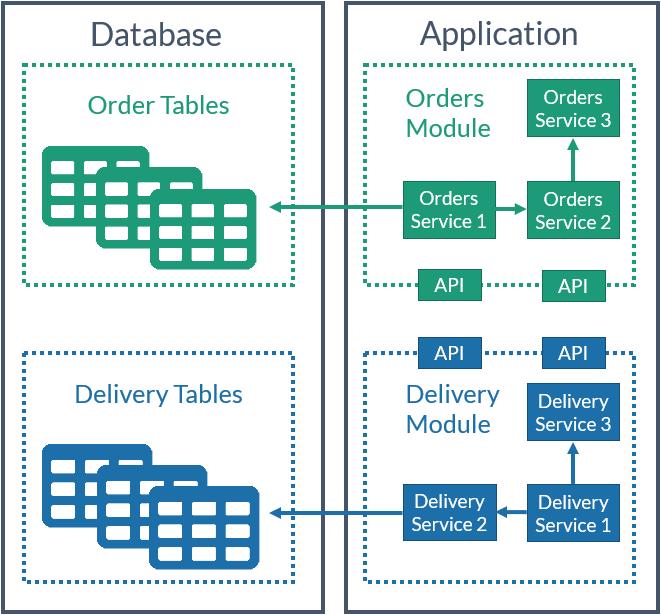
Implementacją kontekstów w aplikacji mogą być np. osobne moduły, które komunikują się przez określone API np. serwisów. Moduły zawierają w sobie zarówno klasy realizujące logikę biznesową jak i schematy przechowywch danych wymaganych w danym kontekście. Ma to na celu zamknięcie odpowiedzialności wewnątrz modułu i udostępnienie tylko takiego jej wycinku, na jaki chcemy pozwolić.
Pomiędzy kontekstami pobieranie i zmienianie danych bezpośrednio przez bazę danych jest mocno odradzane. W przypadku potrzeby zmiany modelu w danym kontekście nie powinniśmy być zmuszeni do modyfikacji całej aplikacji, a jedynie dostosować API do nowego modelu. Aby osiągnąć taki podział nie jest wymagana inna baza danych – jedynie osobny zbiór tabel, które nie są modyfikowane spoza swojego kontekstu.
Załóżmy, że kontekst Delivery pobiera przez API dane o kliencie z kontekstu Orders. Następnie w kontekście Orders wystąpiła potrzeba zmiany modelu klienta na 2 osobne - klienta biznesowego i klienta prywatnego. Jak sobie z tym poradzić?
Published Language
Jednym ze sposobów jest ustanowienie kontraktu, który współdzielimy na zewnątrz. W przypadku zmian w wewnętrznej strukturze potrzebujemy zmodyfikować dostarczanie danych do API by wciąż odpowiadało bez zmian. Czyli nasza wewnętrzna struktura się zmieniła, ale zewnętrzny schemat wciąż jest taki sam. Dzięki temu zewnętrzne konteksty nie wiedzą nic o aktualnej zmianie. Taki model współpracy nazywa się Published Language - od schematu jaki zobowiązujemy się publikować na zewnątrz naszego kontekstu.
Przekładając to na powyższy przykład - nawet jeśli w kontekście Orders zmienimy model Customer na BusinessCustomer i PrivateCustomer to musimy zachować spójność w naszym API. W przypadku żądania z kontekstu Delivery tłumaczymy te 2 modele na jeden ogólny, który zdecydowaliśmy się współdzielić.
Co jednak zrobić, kiedy pracujemy w kontekście Delivery, a kontekst Order nie ukrywa przed nami zmian? Bezpośrednio zmienia modele klienta w wystawianym API? Czy wtedy wszystkie modele w kontekście Delivery są do modyfikacji?
Anti-Corruption Layer
Wzorcem, który pozwala sobie radzić w sytuacji, jest Anti-Corruption Layer. Tworzymy w naszym kontekście warstwę pośredniczącą, w której tłumaczymy modele przychodzące z API na model, który jest używany w naszym kontekście. Takie działanie chroni nasz kontekst przed “korumpującymi” zmianami z zewnątrz - w przypadku zmian musimy zmodyfikować warstwę pośredniczącą, ale nasza logika biznesowa pozostanie bez zmian.
Nawiązując do poprzedniego przykładu - w konktekście Delivery tworzymy warstwę, w której tłumaczymy BusinessCustomer i PrivateCustomer na Customer. Przez nią przechodzą wszystkie żądania do kontekstu Orders. Dzięki temu jedyne miejsce, które wie o zmianach w modelu Customer jest warstwa pośrednicząca. Cała nasza logika biznesowa działa bez zmian.
Zalety implementacyjne kontekstów
Sposobów na integrację konktestów jest wiele, ale najważniejsze jest to co nam daje pojedynczy kontekst. Wszystkie schematy, encje, view modele, serwisy, helpery zawarte w kontekście są teraz jego własnością i nie powinny być edytowane bez wiedzy i zgody właścicieli kontekstu. Takie zachowanie może początkowo utrudniać dokonywanie zmian, ale długoterminowo zyskujemy większą stabilność i szersze zrozumienie do czego służy nasz kod. Łatwiej jest budować collective ownership - wspólną dbałość o dobrą jakość kodu. Wewnątrz konktestu możemy nawet sobie pozwalać na większe zmiany i modyfikować całą architekturę naszego rozwiązania. Musimy jedynie pamiętać o tym by nasze konktrakty wciąż były zachowane.
Comments:
Dlaczego Bounded Contexty są ważne - szkielet implementacji | Radek Maziarka
Dziękujemy za dodanie artykułu - Trackback z dotnetomaniak.pl

