
// wszystkie materiały zostały zebrane w podsumowaniu cyklu.
Punktem, który często pojawia się podczas pisania systemów rozproszonych jest kwestia zapanowania nad spójnością danych. Temat jest bardzo często interpretowany w sposób kompletnie nieprzystający do rzeczywistości, w ramach której pracujemy. Ostateczna spójność (Eventual Consistency) jest odrzucana jako coś niepożądanego. Chcemy osiągnąć natychmiastową spójność, co rodzi więcej problemów niż tworzy zysków.
Rozproszony system zamówień
Załóżmy, że posiadamy rozproszony system e-commerce. Każdy z mikroserwisów realizuje swoją funkcję:
- Stan produktów
- Cenniki
- Rabaty
- Atrybuty i parametry produktu
- Płatności
- Zamówienia
System posiada pewną dozę odseparowania od siebie – niezależne aplikacje i bazy danych. Gdy jednak dochodzi do składania zamówienia, wymagane jest sprawdzenie danych w 5 pozostałych serwisach, by zamówienie mogło zostać zrealizowane. Chcemy mieć natychmiastową spójność – być pewni, że w żadnym z miejsc dane nie zostały zmienione.
Fallacies of distributed computing
Taki sposób tworzenia systemów mógł dawać radę, gdy system działał jako monolit. Mieliśmy połączenia do tej samej bazy danych, wszystko działo się w jednym procesie, łatwo było zawracać transakcje. Niestety, dziś jest inaczej. Teraz głównym trendem jest tworzenie systemów opartych o mikroserwisy. A ten świat rządzi się innymi prawami.
Świat systemów rozproszonych to świat, w którym bardzo dużo rzeczy może pójść nie tak. Sieć może się zerwać, żądanie HTTP może nie dotrzeć do adresata bądź może przyjść zdecydowanie za późno. Zasady, które pozwalały nam tworzyć dobre, monolityczne systemy nie przystają już do świata systemów rozproszonych.
Niestety, nasz mindset wcale nie poszedł do przodu. Dalej staramy się pisać nasze systemy tak, jakby wszystko dało się zapewnić w sposób natychmiastowy. A to powoduje problemy, niekiedy naprawdę nieoczywiste.
Zamówienia jako wąskie gardło
Biorąc powyższe pod uwagę, natychmiastowo rzuca się w oczy pierwszy problem. Nawet jeśli jesteśmy w stanie zapewnić 99% dostępności naszych serwisów, to jeśli w składaniu zamówienia bierze udział 6 takich serwisów, to nasza ogólna dostępność spada do 94% (0.99^6). Czyli zamiast gubić 1 zamówienie na 100 to zaczynamy ich gubić 6 razy więcej.
Standardowym rozwiązaniem w tej sytuacji jest wykorzystywanie powtórzenia żądań. Jednak to nie rozwiązuje do końca naszych problemów. Każde takie zapytanie to czas i zasoby, które są potrzebne do przetworzenia żądania. W drastycznych sytuacjach możemy dojść do momentu, kiedy całe żądanie zostanie anulowane.
 Dodatkowa zależność jest mniej oczywista. Zespoły pracujące nad pozostałymi serwisami muszą synchronizować swoją pracę z zespołem serwisu zamówień. Jeśli chcemy np. dokonać aktualizacji serwisu rabatów i unieruchomić serwis na godzinę to bezpośrednio wpłynie to na składanie zamówień. Żadne z nich nie będzie mogło mieć miejsca przez zadane okienko czasowe.
Dodatkowa zależność jest mniej oczywista. Zespoły pracujące nad pozostałymi serwisami muszą synchronizować swoją pracę z zespołem serwisu zamówień. Jeśli chcemy np. dokonać aktualizacji serwisu rabatów i unieruchomić serwis na godzinę to bezpośrednio wpłynie to na składanie zamówień. Żadne z nich nie będzie mogło mieć miejsca przez zadane okienko czasowe.
To też łączy się z wprowadzaniem jakichkolwiek zmian kontraktu. Nie jesteśmy w stanie dokonać ich w serwisie zależnym, dopóki serwis główny wymaga bezpośrednio tego kontraktu. Wszystkie zmiany muszą być nakładane w tym samym momencie po obu stronach.
Ostatnie 2 punkty są najczęściej pomijane, a wg mnie są najważniejsze i najtrudniejsze, jeśli chodzi o systemy rozproszone. Nasza praca przestaje być odseparowana od siebie – tworzymy sklejone rozwiązanie, które musi działać jako całość, bo inaczej nie działa w ogóle. Zaczynamy tworzyć rozproszony monolit, wypaczając ideę systemów rozproszonych. Wszystkie zalety mikroserwisów idą w piach.
A więc co robić / jak żyć?
Brak systemów informatycznych
Żeby sobie uzmysłowić rozwiązanie tego problemu dobrze jest posłużyć się przykładem z czasów, kiedy jeszcze nie było Internetu, a szczególnie systemów rozproszonych. #KiedyśToByło

Składając zamówienie w sklepie nie było fizycznej możliwości, by za każdym razem sprawdzać poziomy cen czy ilość produktów w hurtowniach. Sklepy posiadały określone informacje w ramach, których działały. Wszystkie operacje zachodziły na miejscu, a tylko przypadki brzegowe były konsultowane dalej. Sklepy był autonomicznym bytem, który mógł działać bez natychmiastowej informacji z zewnątrz.
Ostatecznie informacje docierały do sklepu – aktualizacje cen, możliwe ilości do sprzedaży, nowe parametry towarów. Ale nie były one wymagane, by sklep mógł realizować swoje zamówienia.
Teraz mamy Internet, systemy rozproszone i latające deskorolki (prawie…), ale to nie znaczy, że te reguły warto odłożyć do lamusa. Nawet najprostsze zamówienie w McDonaldzie jest ostatecznie spójne – otrzymanie burgera jest rozłączne od płacenia za niego. Rzeczywistość dookoła nas nie jest natychmiastowo spójna, bo to byłoby zbyt trudne do zrealizowania.
Bounded context i ostateczna spójność
Tutaj dochodzimy do sedna – kontekst (w naszym przypadku w postaci mikroserwisu) jako pojedyncza jednostka spójności jest wobec samej siebie zawsze spójna. Wszystkie zmiany zachodzące wewnątrz niego są pewne. Ale nie powinien się starać za wszelką cenę być spójny z pozostałymi kontekstami. To by łamało autonomię i zmuszało do rozległych koordynacji.
Koordynacja jest osiągana za pomocą:
- Komunikatów asynchronicznych – kontekst informuje pozostałe konteksty np. kolejką, że nadeszła zmiana
- Sag – wzbudzany jest proces poboczny, który następnie zarządza koordynacją informacji
- Zdarzeń – konteksty poboczne informują kontekst zależny, w ramach odwrócenia zależności
Takie działania pozwalają nam na osiąganie ostatecznej spójności, jednocześnie nie wymuszając natychmiastowej synchronizacji pomiędzy kontekstami.
E-commerce i ostateczna spójność
Tłumacząc to na nasz system e-commerce – serwis zamówień jako pojedynczy kontekst będzie spójny wewnętrznie tzn. sprzeda towary wg. swojej aktualnej wiedzy. Mamy 100% pewność, że udało się złożyć zamówienie wg. określonych kryteriów ceny, ilości i parametrów.
Jednak nie mamy 100% pewności np. że ceny są dokładnie takie jak w kontekście cenników. Najczęściej tak będzie, ale przez możliwe kilkusekundowe opóźnienie w transporcie danych może zdarzyć się rozbieżność. Jednak po tym czasie zmiany zostaną naniesione na kontekst zamówień i system ostatecznie będzie spójny.

W podobny sposób zarządza się ilością towarów. Systemy e-commerce stawiają na rozdział pomiędzy stanem sprzedażowym a stanem magazynowym. W kontekście zamówień mamy możliwość sprzedawania towaru, którego realnie nie posiadamy. Na podstawie zamówień kontekst stanu produktów informowałby, że danego towaru jest aktualnie za mało i należy go dokupić / wyprodukować.
Taki podział sprawia, że mamy dobrze odseparowane odpowiedzialności i możemy pracować w niezależny sposób. Na pierwszy rzut oka wygląda to niepokojąco, ale tak działają największe platformy e-commerce na świecie i w Polsce. Np. Amazon wysyła na Kindla e-booka natychmiast po kliknięciu KUP, nie patrząc czy płatność się zakończyła. Pozwala to skupić się na zadowoleniu klienta i zająć się księgowaniem później.
Czy zawsze warto?
Oczywiście aktualnie dalej jesteśmy w stanie tworzyć systemy, które są silnie spójne, wykorzystując do tego odpowiednie wzorce i bazy danych np. CosmosDB i jego różne poziomy spójności. Można też spróbować rozwiązywać opisane wyżej problemy za pomocą skomplikowanych wdrożeń i rozwiązań technicznych z obszarów Service Meshy. Ma to jednak swoje wady:
- Raz, że mamy spadki na wydajności spowodowane narzutem komunikacyjnym i synchronizacyjnym.
- Dwa, że bardzo trudno stworzyć taki model danych który spełni naraz wszystkie przypadki biznesowe.
- Trzy, że te rozwiązania techniczne też mają swój poziom skomplikowania, często o wiele wyższy niż rozwiązania związane z kontekstami i ostateczną spójnością.
O wiele lepiej jest operować na biznesowych scenariuszach i konsultować przypadki brzegowe z ludźmi, którzy żyją nimi na co dzień. Świetnie skwitował to Kacper Gunia na konferencji Explore DDD:

Bardzo często będziemy zaskoczeni jak coś, co dla nas mogło być nie do zaakceptowania, będzie bez przymrużenia okiem zaakceptowane przez ekspertów domenowych. Dla nich np. synchronizacja informacji w ciągu 2 sekund jest tak absurdalnie niska, że w zasadzie pomijalna. A jeśli jakiś towar sprzedaje się tak szybko, że nie dajemy radę sprawdzać jego stanów magazynowych to jest to raczej wskazanie, by ich nie sprawdzać w ogóle 😉
Ostateczna spójność a myślenie systemowe
Jeśli po przeczytaniu tego artykułu dalej masz w głowie takie przemyślenie: „Co mnie obchodzą możliwe problemy – po to tworzę system informatyczny, by mieć to w jednym miejscu spójnie” to może trafi do Ciebie poniższy argument.
Systemy rozproszone mogą być postrzegane jako podzbiór systemów złożonych. Czyli są (bądź powinny być) zmieniające się w czasie, adaptowalne, odporne na problemy / uszkodzenia. Aby jednak systemy posiadały takie przymiotniki potrzebne są też pewne komponenty, które pozwolą mu działać w opisany sposób.
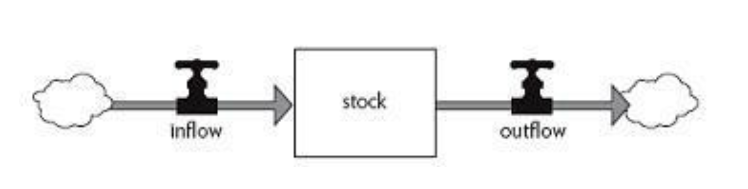
W książce Thinking in Systems Donatella Meadows świetnie opisała koncept zapasów (stock) – buforów, które przetrzymują materiały do wykorzystania dalej. Poszczególny komponent systemu jest w stanie generować rezultat (outflow) bez napływu dodatkowych materiałów (inflow). Nie jest to działanie długotrwałe, ale krótkofalowo potrafi uchronić daną część od możliwych problemów.
W taki sposób działają np. nasze organizmy (gromadząc pożywienie do następnego posiłku), firmy (trzymając pieniądze na nieprzewidziane sytuacje) czy całe społeczeństwa (akumulując wodę w stawach na wypadek suszy). Zapas wiąże się z oczywistymi problemami: niewykorzystane jedzenie jest usuwane bądź odkłada się, kasa trzymana na koncie nie pracuje na zysk firmy, a staw zajmuje miejsce i wymaga utrzymywania go. Ogólnie patrząc - generuje straty bądź zmniejsza zyski. Posiada jednak ogromną zaletę – absorbuje potencjalne problemy, które mogą wystąpić w pozostałych częściach systemu. Dzięki temu zyskujemy odporność pozwalającą nam działać nawet w trudnych sytuacjach.
To nawiązuje do działania naszego systemu informatycznego. Nie możemy w każdej sytuacji polegać na pozostałych serwisach, ponieważ znacznie podwyższą one naszą podatność na problemy. Akumulacja wiedzy jako zapasów pozwala działać w sposób odseparowany i niezależny w stosunku do reszty systemu. A ostateczna spójność jest sposobem, by ten materiał wykorzystać.
Comments:
Dlaczego Bounded Contexty są ważne – ostateczna spójność | Radek Maziarka
Dziękujemy za dodanie artykułu - Trackback z dotnetomaniak.pl

