
Kontynuujemy cykl o modelowaniu w Cosmos DB. W poprzednim odcinku określiliśmy kilka propozycji struktury bazy daych. Następnie wykonaliśmy ich ewaluację, odrzucając nieefektywne modele.
W tym odcinku zastanowimy wybierzemy 2 struktury do dalszych testów . Tak, 2 struktury 😀 - dalej nie będziemy mieli jednego rozwiązania docelowego. Poniżej dowiecie się dlaczego!
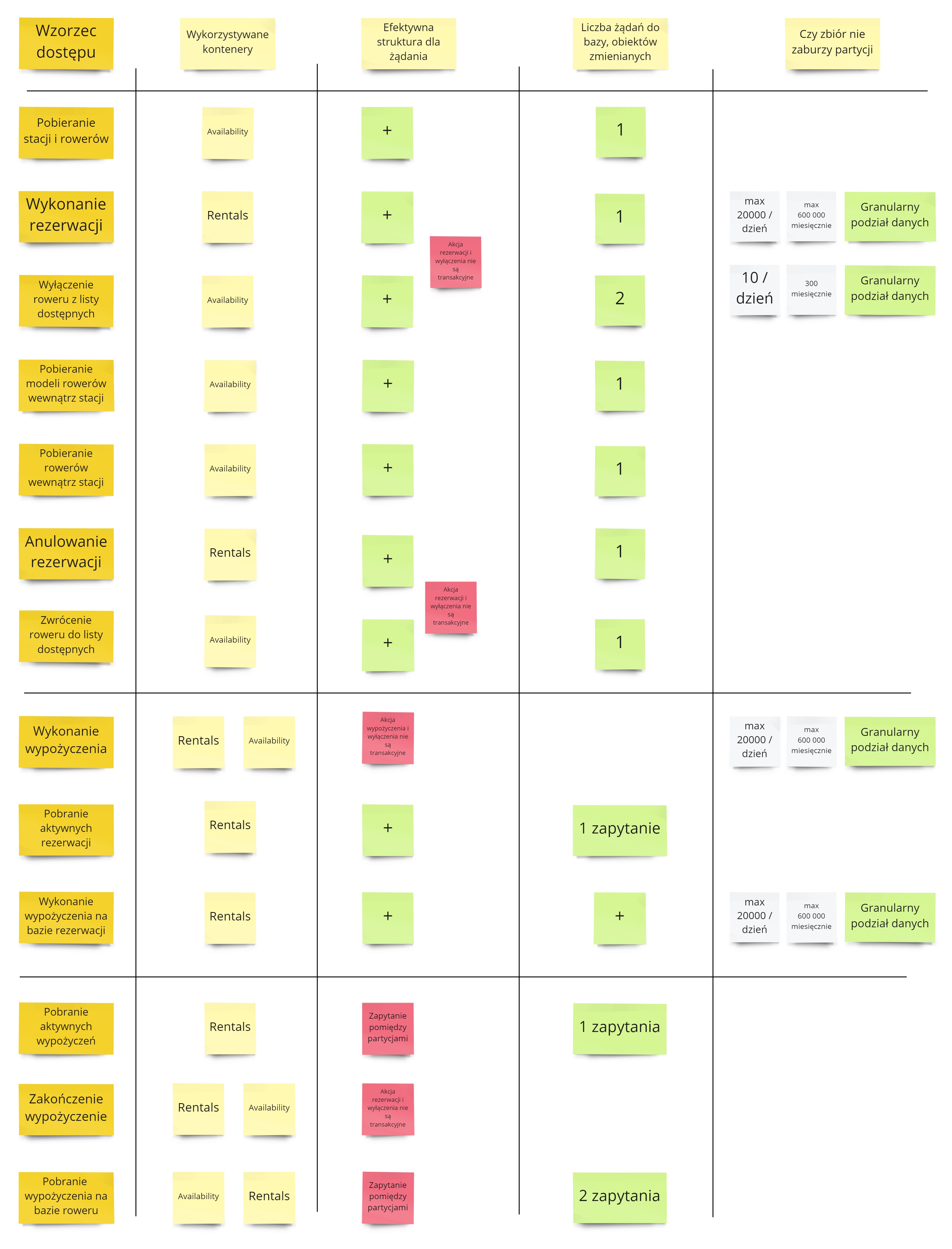
Jakie mamy wynikowe struktury danych?
Podczas analizy wyszło nam, że dla przetrzymywania obiektu Bike Avaiability mamy w zasadzie tylko jedną opcję - partycjonowanie po CityId.
Z drugiej strony dla obiektów Reservation i Rental możemy mieć dwie opcje:
- Partycjonować po UserId
- Partycjonować po CityId i dniu - wykorzystując klucz syntetyczny
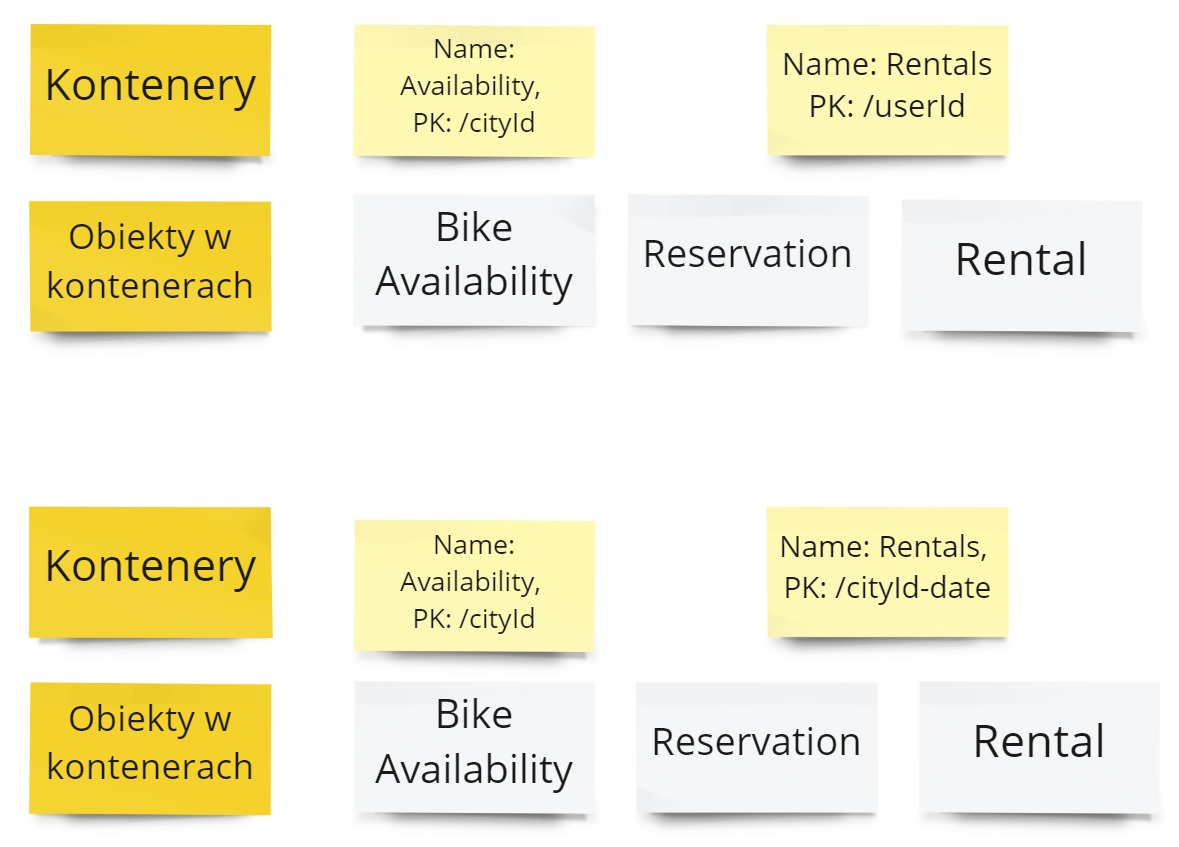
Każda z opcji posiada swoje plusy i minusy. Wszystkie one są umieszczone pod linkami - obrazki analiz nie zmieściłyby się na blogu 😅:
Dlaczego wybieramy dwie struktury danych?
Na obecnym poziomie nie da się dokładniej porównać kosztowności obu rozwiązań. Mamy konkurencyjne struktury, które na papierze wyglądają bardzo podobnie. Tylko bezpośrednie uruchomienie danej struktury może nam odpowiedzieć na pytanie jak ona się sprawdza.
W świecie drogich zasobów musielibyśmy aktualnie podjąć arbitralną decyzję. Wybralibyśmy jeden model kosztem drugiego. Zaczęlibyśmy tworzyć rozwiązanie produkcyjne, które ostatecznie mogłoby się nie sprawdzić.
Ale nie jesteśmy w świecie drogich zasobów 💪 Możemy niskim kosztem stworzyć naszą bazę. Następnie usunąć ją, kiedy nie jest już potrzebna. Nic nie stoi na przeszkodzie, by przetestować kilka opcji na rzeczywistych przypadkach. Wtedy sprawdzimy, która z nich jest aktualnie lepsza.
Takie podejście bazuje na modelu Cynefin Dave’a Snowdena, gdzie dzielimy problemy na 4 rodzaje:
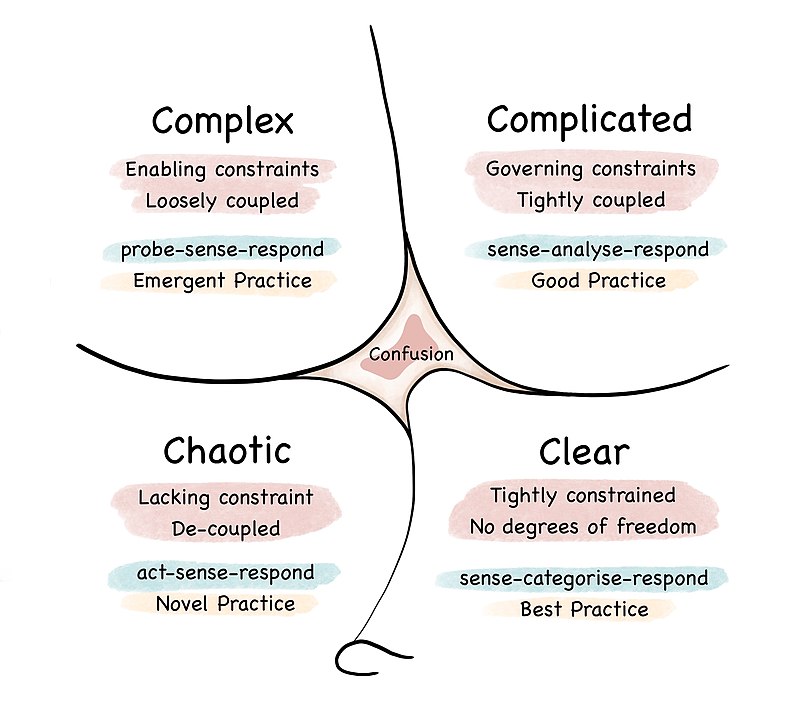
Model Cynefin mówi, aby w obszarach dużej niepewności wykorzystywać bezpieczne ekspermenty (safe-to-fail probes), aby sprawdzić jak dany scenariusz sprawdza się w praktyce.
A co będziemy testować? Przede wszystkim liczbę zużywanych RU.
Request Unit - koszty zapytań
W Cosmos DB koszt wszystkich operacji jest wyliczany na bazie wykorzystywanych zasobów:
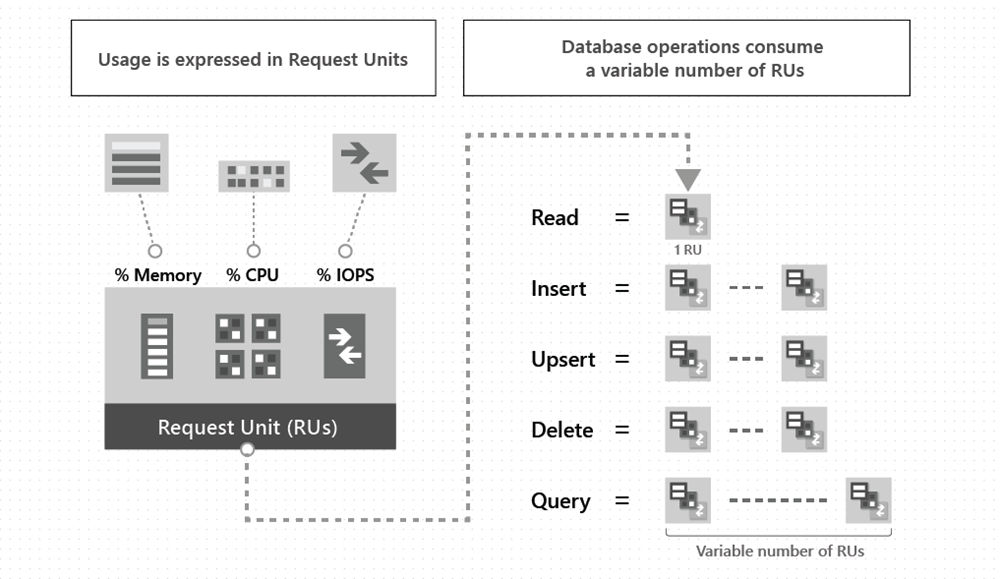
Im więcej dane zapytanie zużyje pamięci / CPU / dysku tym więcej będzie kosztowało nas zapytanie.
Koszt zapytania jest wyrażony w Request Unitach - RU. Zapytanie kosztuje:
- Odczyt obiektu - 1RU za każdy KB - dokumentacja
- Dodanie, edycja, usunięcie obiektu - ~5.5RU za każdy KB + RU za indeksację - dokumentacja
- Wyszukiwanie obiektów - sky is the limit 😅 - dokumentacja
Zapytania są najdroższym elementem wykorzystania Cosmos DB. Przeprowadzając nieefektywne zapytania będziemy dramatycznie mnożyć koszty. Z tego powodu istotne jest zrozumienie scenariuszy wykorzystania bazy danych. Tworząc rozwiązanie w ciemno bardzo łatwo jest wpaść na minę i zbudować niewłaściwą strukturę bazy danych.
Więcej o samych kosztach Cosmos DB w dokumentacji Microsoftu. Powiemy sobie o nich również więcej w kolejnych odcinkach cyklu, gdy będziemy wybierali model rozliczania się.
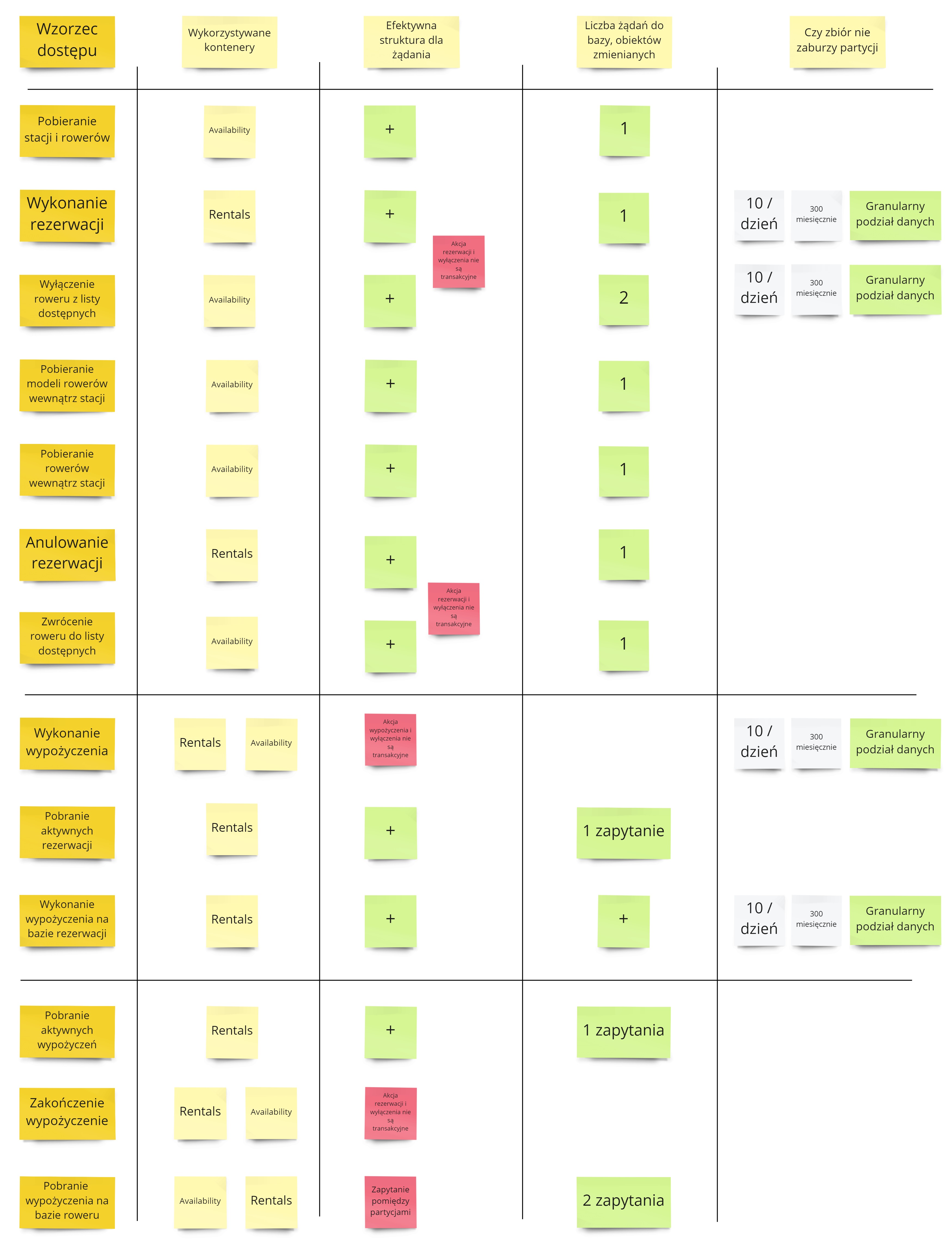
Scenariusz testowy
A więc jak może wyglądać nasz scenariusz testowy?
- Stwórz strukturę bazodanową odpowiednią na podstawie prostych skryptów CLI.
- Zapełnij bazę przykładowymi, ale rzeczywistymi danymi.
- Sprawdź kosztowność zapytań przechodząc przez wzorce dostępu.
- Porównaj rezultaty dla obu struktur.
Ale to już w kolejnych artykułach 😎


{kind=link}
{kind=link}