
This week my godfather asked me for a favor. He works in an agricultural conglomerate and is responsible for soil researchers for their clients. Currently, he found a document which covers analysis the soil, from 1995 to 2015, with an incredible amount of data. There are sheets with multiple examinations of soils every 5 years with an exact number of particular chemical elements and its absorption, as well as other parameters as saltiness, electric conductance etc. He asked me:
Radek, is there a possibility to find the correlation between a particular chemical element and how much of it can be effectively used?
I heard that machine learning can simplify finding an answer to such question so I decided to look into it. And because I knew that Microsoft Azure has its own Azure Machine Learning I thought that it is worth trying. So I did and I am amazed how such technologies are approachable these days.
So how to start with such task? Let me explain:
- Preparing data
- Creating experiment
- Choosing relevant parameters
- Choosing algorithms
- Training the model
- Evaluating models
- Summary
Azure Machine Learning portal
Isn’t it remind you something? ;)
Preparing Data
For most of your cases, this will be most time-consuming and annoying part.
In real life, data can be stored in multiple files / pages / databases and you need to combine it into one file. CSV file, text file or something similar - it needs to be easily readable so, unfortunately, no Excel files.
Moreover, you need to remember about cleaning data process - removing or fulfilling empty values, provide proper names for the columns, replacing not meaningful values (<0.1 won’t be understandable) and others. Without it, your data will contain a mess that will disturb the experiment and lead to the wrong conclusion.
If you need to convert data from PDF file I can recommend you PDFtoExcel website, works properly even with a very large document.
Then you need to add this CSV file to DATASETS section. As you can see, I focused on phosphorus and its absorption.
Creating experiment
Then, with delivered data, you can start your experiment. You need to go to EXPERIMENTS tab, create a blank experiment and name your experiment. Then you can drag-and-drop your data from Saved Datasets. Everything there works as drag-and-drop, and connecting blocks - pretty awesome.
Choosing relevant parameters
TBH: At the beginning, my girlfriend, who is a Data Scientist, helped me to find relevant parameters. But later, I found in Azure Machine Learning portal option to do such thing so I wanted to share this knowledge with you.
Usually part of the data won’t be relevant to your desired value - it is stored along with other significant parameters, but it could lead to a wrong calculation. So better is to remove it before trying our calculations.
So you need to find Filter Based Feature Selection block from Feature Selection menu.
Then, after running your experiment, you will get a list of parameters with a correlation:
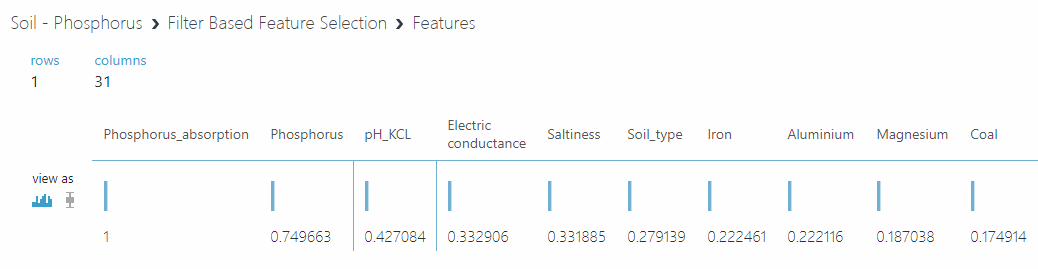
Choosing algorithms
The second important thing to consider in your experiment is which particular algorithm you need to use to find a solution. Fortunately, Azure Machine Learning contains an algorithm cheat sheet which leads you by the hand to find the best fitting algorithm to your problem.
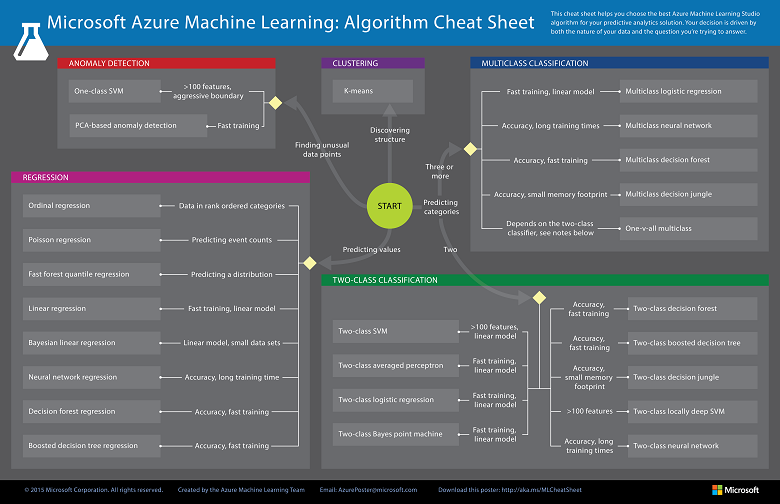
In my circumstances, I had to predict an absorption by the variety of parameters so I decided to use 2 algorithms: linear regression,and decision forest regression.
Training the model
Training your model is running chosen algorithms to find what is the best patterns that map the variables to the target, and outputs model that captures these relationships.
You need to remember that you cannot train your model on a whole amount of data - some part is needed to check if a trained model properly returns the correct value.
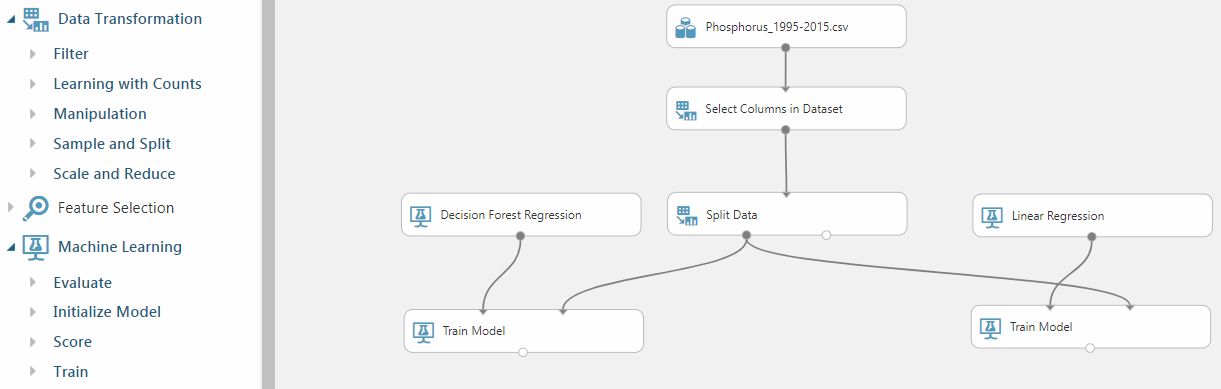
To train your model you need:
- Select preferred parameters - **Select Columns in DataSet **in Data Transformation -> Manipulation
- Separate data in 2 chunks - **Split Data **in Data Transformation -> Sample and Split
- Add algorithms - Decision Forest Regression / **Linear Regression **in Machine Learning -> Initialize Model
- Run training - **Train Model **in Machine Learning -> Initialize Model
After running the experiment you will get a trained model with result parameters / decision trees.
Evaluating models
With a trained models you can go to the part where we check if a trained model might help you find a correlation between parameters and required value.
At the beginning, you need to check if trained model works well with the rest amount of data. To do it you connect **Score Model **(Machine Learning -> Score) to result of the Trained Model with the second output of Split Data.
Then concat outputs of Score Models into **Evaluate Model **(Machine Learning -> Evaluate) to check the results.
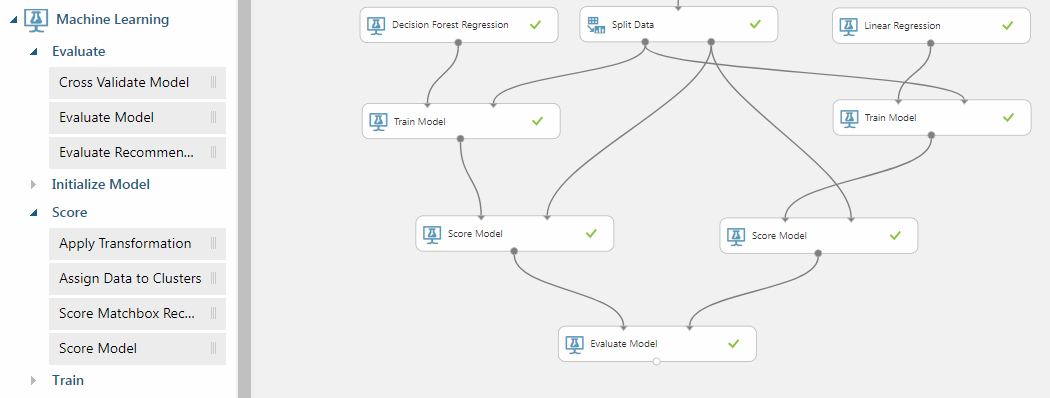
Opening model evaluation will result with such view:
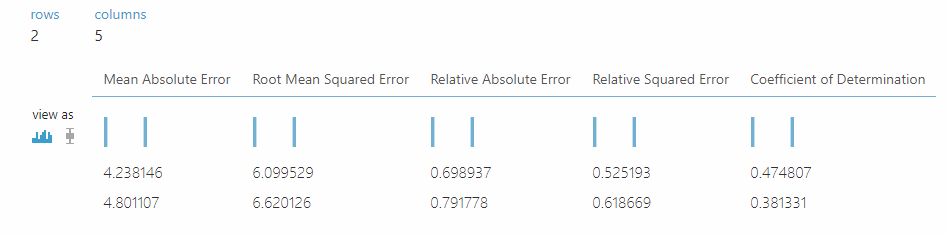
Coeffient of Determination under 0.5 is recognized as the **unsatisfactory match **so unfortunately, with our data, we won’t be able to create the model to calculate phosphorus absorption. But there are other chemical elements in the document so we will try to investigate them as well.
Summary
Azure Machine Learning is easily approachable and powerful platform to provide machine learning components in developers life. There are varieties of materials (MSDN), blogs, and videos (Pluralsight) explaining how to choose algorithms, parameters, and help you go through the process of calculation.
With a better knowledge of how machine learning works and how to connect it to an existing application, you would be able to provide greater value to your customers and clients. Nowadays data is everywhere, the only thing is to know how to use it.
Azure Machine Learning is free and does not require Azure subscription (link) so you can start your journey today ;)
Comments:
Azure Machine Learning – so god damn easy | Radoslaw Maziarka Blog
Dziękujemy za dodanie artykułu - Trackback z dotnetomaniak.pl

