This post series is driven by my lightning talk about how to introduce CQRS to your project. I thought that would be good to explain this topic further for people who won’t be attending my presentation.
I will write about:
- splitting code to commands and queries
- introducing different data access
- creating simple read model
- creating read model asynchronously with SignalR notification
You can find source codes here.
Stay tuned ;)
Recent state of your app
After the previous step, you have refactored plenty of your services into separated queries and commands - applied first step in CQRS pattern. Few of services stayed the same, but they contained only 1 or two methods, so you decided to concentrate on things that matters and the rest leave it is.
Now your application logic is defined in small, highly boundaried objects which are easier to tests and maintain. Unfortunately, it is only a structural change - you haven’t improved the performance of your application. But with such clearly defined responsibilities you are able to find bottlenecks and do something with them.
Your current bottleneck - slow querying:
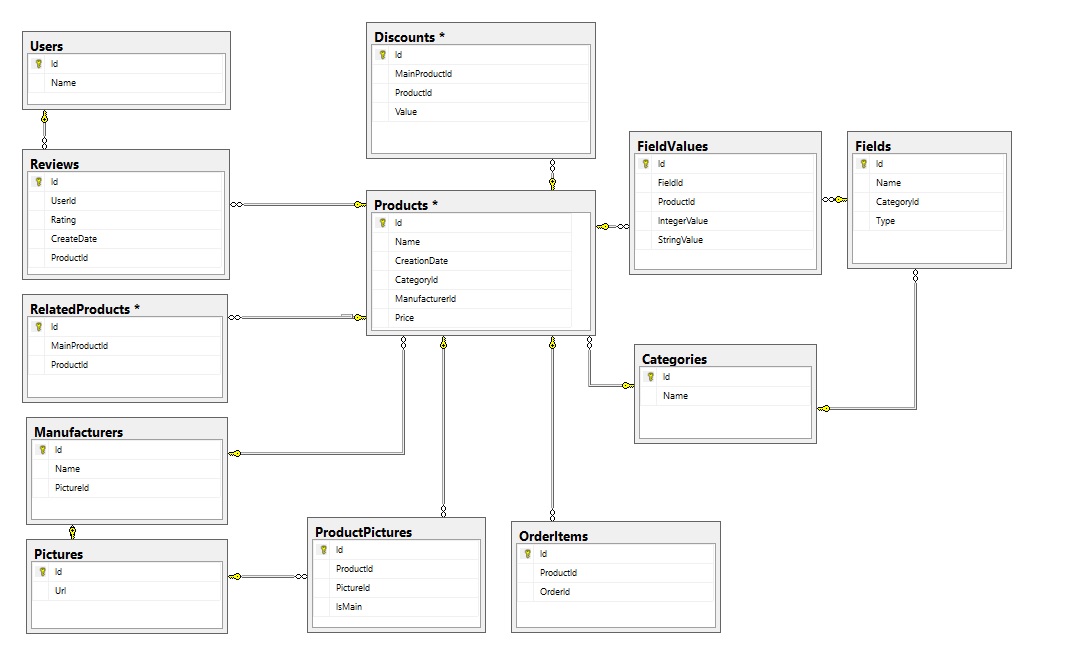
You find your first bottleneck - gathering product’s offer currently is taking too much time, freezing user interface and blocking to do anything. Currently, your users don’t apply advanced filterings or querying, but even without them reading data is slow and insufficient. When you look into it you realize that your query handler is trying to get too much data in one call which results with enormous SQL query.
public class GetProductsQueryHandler : IRequestHandler<GetProductsQuery, IEnumerable<Product>>
{
private readonly ProductDatabase _database;
public GetProductsQueryHandler(ProductDatabase database)
{
_database = database;
}
public IEnumerable<Product> Handle(GetProductsQuery command)
{
var products = this._database
.Products
.Include(p => p.Category)
.Include(p => p.Pictures)
.Include(p => p.Manufacturer)
.Include(p => p.Manufacturer.Picture)
.Include(p => p.RelatedProducts)
.Include(p => p.RelatedProducts.Select(rp => rp.Product))
.Include(p => p.RelatedProducts.Select(rp => rp.Product.Pictures))
.Include(p => p.OrderItems)
.Include(p => p.FieldValues)
.Include(p => p.FieldValues.Select(fv => fv.Field))
.Include(p => p.Reviews)
.Include(p => p.Reviews.Select(r => r.User))
.Include(p => p.Discounts)
.Include(p => p.Discounts.Select(d => d.Product))
;
if (command.CategoryId.HasValue)
{
products = products.Where(p => p.CategoryId == command.CategoryId);
}
return products
.OrderBy(p => p.CreationDate)
.Skip((command.Page - 1) \* command.Take)
.Take(command.Take)
.ToList();
}
}
With such state of the database (diagram / code) such querying can take a while. Of course, you can split your query and do multiple requests to the database but it only hides the problem but doesn’t solve it. You realize that you need only a small amount of this information from queried objects, but they are significant to fulfill clients' needs - we need to show product list with:
- Category name
- Main picture
- Manufacturer name and picture
- Related products with pictures
- How many time product has been bought
- Product’s field values
- Average review ratings and last 5 reviews
- 3 best discounts for this product
So you decide to do something different - change your query model and introduce new option to access database that will allow doing more advanced querying.
It would be more difficult to introduce it with your previous, service pattern, but with current query-command orientation it is really easy because you are not breaking any other part of the system - you focus only on the current object and refactor to toward higher value.
Different data access
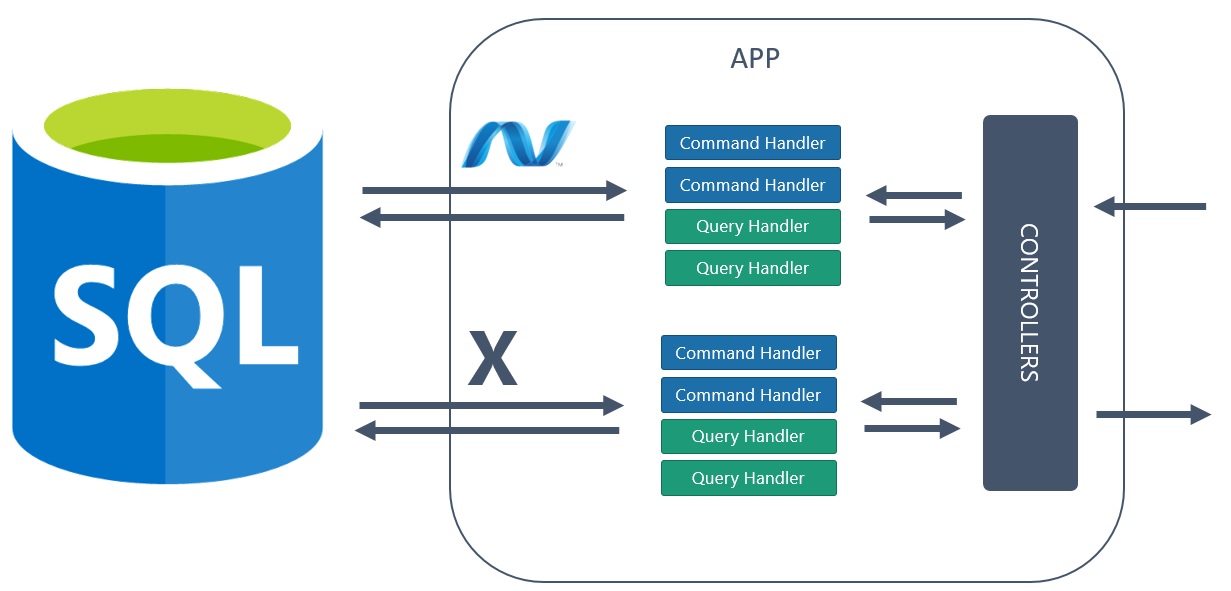
Different data access is a realization of a simple thought:
You can access your database differently, depending on a case.
Going back to our case, there are many ways to introduce different read model to your app, each with different advantages and disadvantages. You can connect directly to a database and apply SQL querying, create SQL view, use different ORM or apply some changes in current ORM to make it more lightweight and faster.
So at the beginning, you define your read model - objects to be retrieved from the database. Then you decide to implement this model in 2 different approaches: Dapper - MicroORM and AutoMapper + ProjectTo to find best fitting one:
Dapper - MicroOrm
Dapper is a light ORM created by StackExchange - question and answer platform that we continuously use in our everyday work (StackOverflow FTW). It allows to connect directly to the database and operate on a low level, manipulating with resulted objects and returning multiple different rows.
You define a tailored-made SQL query to get an exact amount of data that you need.
CREATE TABLE #Products
(
Id int,
Name NVarchar(128),
Price decimal,
CategoryName NVarchar(128),
PictureUrl NVarchar(max),
ManufacturerName NVarchar(128),
ManufacturerMainPictureUrl NVarchar(max),
OrdersNumber int,
AverageReviewRating float
)
-- Products to temporal table
INSERT INTO #Products
SELECT
P.Id, P.Name, P.Price,
C.Name AS CategoryName,
PPP.Url AS MainPictureUrl,
M.Name AS ManufacturerName,
MP.Url AS ManufacturerMainPictureUrl,
(SELECT TOP 1 COUNT(\*) FROM OrderItems AS OI WHERE P.Id = OI.ProductId GROUP BY OI.ProductId) AS OrdersNumber,
(SELECT TOP 1 AVG(R.Rating) FROM Reviews AS R WHERE P.Id = R.ProductId GROUP BY R.ProductId) AS AverageReviewRating
FROM dbo.Products AS P
INNER JOIN Categories C ON P.CategoryId = C.Id
LEFT JOIN ProductPictures PP ON PP.ProductId = P.Id AND PP.IsMain = 1
LEFT JOIN Pictures PPP ON PPP.Id = PP.PictureId
INNER JOIN Manufacturers M ON P.ManufacturerId = M.Id
LEFT JOIN Pictures MP ON M.PictureId = MP.Id
WHERE @CategoryId IS NULL OR P.CategoryId = @CategoryId
ORDER BY P.Id
OFFSET @Take \* (@Page - 1) ROWS
FETCH NEXT @Take ROWS ONLY;
-- Query all found products
SELECT \* FROM #Products
-- Query related products
SELECT
RP.MainProductId, RP.ProductId,
P.Id, P.Name AS ProductName,
PPP.Url AS PictureUrl
FROM RelatedProducts RP
LEFT JOIN Products P ON RP.ProductId = P.Id
LEFT JOIN ProductPictures PP ON PP.ProductId = P.Id AND PP.IsMain = 1
LEFT JOIN Pictures PPP ON PP.PictureId = PPP.Id
WHERE RP.MainProductId IN (SELECT Id FROM #Products)
-- Query field values
SELECT
FV.ProductId, FV.StringValue, FV.IntegerValue,
F.Name AS FieldName, F.Type AS FieldType
FROM FieldValues FV
INNER JOIN Fields F ON FV.FieldId = F.Id
WHERE FV.ProductId IN (SELECT Id FROM #Products)
-- Query latest reviews
SELECT TOP 4
R.Rating, R.CreateDate, R.ProductId,
U.Name AS UserName
FROM Reviews R
JOIN Users U ON R.UserId = U.Id
WHERE R.ProductId IN (SELECT Id FROM #Products)
ORDER BY R.CreateDate DESC
-- Query discounts
SELECT TOP 3
D.Value, D.MainProductId, D.ProductId,
P.Name AS ProductName
FROM Discounts D
JOIN Products P ON D.ProductId = P.Id
WHERE D.MainProductId IN (SELECT Id FROM #Products)
ORDER BY D.Value DESC
DROP TABLE #Products
First, you define a temporal product table and put all products into it. Then you write multiple SELECT queries to gather all data in one query - first to get products and then related products, field values, reviews and discounts. Not a single excessive field is returned from the database.
After it, with the power of Dapper, you are parse data to strongly-typed classes and combine related objects with parent products.
public class GetProductsQueryHandler : IRequestHandler<GetProductsQuery, IEnumerable<ProductVm>>
{
private readonly SqlConnection _connection;
public GetProductsQueryHandler(SqlConnection connection)
{
_connection = connection;
}
public IEnumerable<ProductVm> Handle(GetProductsQuery command)
{
List<ProductVm> products;
var sqlQuery = QueryHelper.GetQuery<GetProductsQueryHandler>();
using (var multi = _connection.QueryMultiple(sqlQuery,
new { command.Page, Take = command.Take, CategoryId = command.CategoryId }))
{
var products = multi.Read<ProductVm>().ToList();
var relatedProducts = multi.Read<RelatedProductVm>().ToList();
var latestReviews = multi.Read<ReviewVm>().ToList();
var fieldValues = multi.Read<FieldValueVm>().ToList();
var discounts = multi.Read<DiscountVm>().ToList();
products.ForEach(p =>
{
p.RelatedProducts = relatedProducts.Where(r => r.MainProductId == p.Id).ToList();
p.FieldValues = fieldValues.Where(r => r.ProductId == p.Id).ToList();
p.LatestReviews = latestReviews.Where(r => r.ProductId == p.Id).ToList();
p.BestDiscounts = discounts.Where(r => r.MainProductId == p.Id).ToList();
});
return products;
}
}
}
Advantages:
- Almost that fast as SQL
- Returning multiple datasets in one query
- Built-in mapping
Disadvantages:
- Mixing SQL and C#
- Harder to maintain
AutoMapper + ProjectTo
AutoMapper is a library which allows creating a mapping from / to classes and handles this whole logic in one mapper. It was created by, already mentioned, Jimmy Bogard.
ProjectTois an extension to this library. It allows you to define mappings from database entities directly to view models. Then you query your database but, at the end, you map (project) your response to a defined view model.
What is really worth mentioning, is that with ProjectTo you can do the stuff, which you can typically do in normal mappings:
- Mapping arrays
- Aggregating (sum / average / max / min)
- Getting first or last
- Flattening objects
So you create a map which defines your expectations. Because of conventions (Category.Name will be automatically transferred into CategoryName) this map is not so hard to read and maintain.
public class GetProductsQueryHandlerProfile : Profile
{
public GetProductsQueryHandlerProfile()
{
this.CreateMap<Product, ProductVm>()
.ForMember(p => p.PictureUrl, m => m.MapFrom(p => p.Pictures.FirstOrDefault(pc => pc.IsMain).Picture.Url))
.ForMember(p => p.ManufacturerMainPictureUrl, m => m.MapFrom(p => p.Manufacturer.Picture.Url))
.ForMember(p => p.OrdersNumber, m => m.MapFrom(p => p.OrderItems.Count))
.ForMember(p => p.AverageReviewRating, m => m.MapFrom(p => p.Reviews.Select(r => r.Rating).DefaultIfEmpty(0).Average()))
.ForMember(p => p.LatestReviews, m => m.MapFrom(p => p.Reviews.OrderByDescending(r => r.CreateDate).Take(5)))
.ForMember(p => p.BestDiscounts, m => m.MapFrom(p => p.Discounts.OrderByDescending(r => r.Value).Take(3)))
;
this.CreateMap<RelatedProduct, RelatedProductVm>()
.ForMember(p => p.PictureUrl, m => m.MapFrom(p => p.Product.Pictures.FirstOrDefault(pc => pc.IsMain).Picture.Url));
this.CreateMap<FieldValue, FieldValueVm>();
this.CreateMap<Review, ReviewVm>();
this.CreateMap<Discount, DiscountVm>();
}
}
After that your simplify query handler because you don’t need all these includes - you use ProjectTo to map SQL data to your ProductVm.
public class GetProductsQueryHandler : IRequestHandler<GetProductsQuery, IEnumerable<ProductVm>>
{
private readonly ProductDatabase _database;
public GetProductsQueryHandler(ProductDatabase database)
{
_database = database;
}
IEnumerable<ProductVm> IRequestHandler<GetProductsQuery, IEnumerable<ProductVm>>.Handle(GetProductsQuery command)
{
var products = this._database.Products;
if (command.CategoryId.HasValue)
{
products = products.Where(p => p.CategoryId == command.CategoryId);
}
return products
.OrderBy(p => p.CreationDate)
.Skip((command.Page - 1) \* command.Take)
.Take(command.Take)
.ProjectTo<ProductVm>
.ToList();
}
}
Advantages:
- Default conventions
- Ease of object / array mapping
- Aggregate functions
- Great association with Entity Framework
- Everything is done in C# code
Disadvantages:
- No possibility for database tweaks
- Slower than other more database-centric solutions (but still fast)
Comparing Dapper and AutoMapper + ProjectTo
Both of these options are worth trying and implement in your project.
AutoMapper / ProjectTo is easier it approach; you don’t need any unknown syntax or behaviors. It is a broadly known Entity Framework, only extended, “on steroids”. Moreover, you don’t need to be familiar with SQL syntax and querying - under the hood, it just works.
Dapper is more powerful and closer to a database - you can optimize your queries on a lower level and gain additional performance.
Summary
The second step to implement CQRS in your project is pretty straightforward - focus on most annoying bottlenecks of your application and improve its performance through applying a different approach to read model. With splitting services to command and queries, there is no need to apply a new query model to a whole application. You can try with vary of frameworks to find most fitting to in your context - SQL Views, MicroORMs, AutoMapper + ProjectTo and others. Implement them, measure if you gained value, and then spread to other parts of your system.
This approach has its own limitation - with adequately complicated database structure, even low-level querying in SQL view can be not sufficient. But in a great amount of cases, you can boost the effectiveness of your application with no difficulties.
For these other, more complicated cases, stay tuned for next posts ;)
Comments:
CQRS – Second step – Simple read model | RadBlog
Dziękujemy za dodanie artykułu - Trackback z dotnetomaniak.pl


{kind=link}